IGNOU BCS-053-Web Programming, Latest Solved Assignment (July 2023 - January 2024 )
Q2) a) Explain the following with the help of a diagram/example, if needed:
(i) Client-Server 2-Tier architecture and its advantages
Ans. Client-Server 2-Tier Architecture:
Client-Server 2-Tier architecture, also known as two-tier architecture or client-server model, is a software architecture pattern where the application’s functionality is divided into two main components: the client and the server. These components interact to provide a user interface (client) and manage data storage and processing (server).
Here's a basic explanation along with a diagram:
1. Client Tier: The client tier is responsible for presenting the user interface and interacting with the user. It could be a desktop application, a mobile app, or a web browser. The client handles user input, displays data, and sends requests to the server.
2. Server Tier: The server tier manages data storage, processing, and business logic. It responds to client requests by retrieving and manipulating data, and then sends the processed information back to the client.
Advantages of Client-Server 2-Tier Architecture:
1. Simplicity: The architecture is straightforward and easy to understand, with the client handling the user interface and the server managing data and processing.
2. Performance: Data processing and business logic are centralized on the server, which can handle heavy computations and data manipulation more efficiently than a client
device.
3. Scalability: Servers can be upgraded or expanded to handle increased load and traffic, ensuring better scalability.
4. Data Security: Centralized data management on the server allows for better control and security measures to protect sensitive information.
5. Maintenance: Updates and modifications can be made on the server side without affecting the client, simplifying maintenance and reducing the need for client-side updates.
6. Resource Utilization: Client devices can be simpler and have fewer hardware requirements, as most processing happens on the server.
Example Diagram:
Client Device Server
+————–+ Request +————–+
| User Interface|——————->| Data Storage |
| Processing |<——————-| & Processing|
+————–+ Response +————–+
In this diagram, the client device interacts with the user interface and sends requests to the server. The server manages data storage and processing and responds to the client’s requests with processed data.
Keep in mind that while the two-tier architecture has its advantages, it might not be suitable for all types of applications, especially those requiring more complex scalability, fault tolerance, or separation of concerns.
(ii) Illustration of MVC architecture (other than the one given in the Block 2 Unit 1)
Ans. The MVC architecture separates an application into three main components: the Model, the View, and the Controller. Here’s an example with a different context:
Let’s consider an online shopping platform as an example of the MVC architecture.
1. Model: The Model represents the application’s data and business logic. In this context, the Model would manage product data, user profiles, shopping cart contents, and order history. It performs operations like retrieving and updating product information and user data.
2. View: The View is responsible for presenting data to the user. It displays product listings, shopping cart contents, and order summaries. In our example, the View would generate HTML pages with product images, descriptions, and prices, allowing users to browse and select items.
3. Controller: The Controller handles user interactions and manages the flow of data between the Model and the View. It receives user input, such as adding items to the cart or completing an order. Based on the user’s actions, the Controller communicates with the Model to update the data and coordinates with the View to display the appropriate information.
Illustration of MVC for Online Shopping Platform:
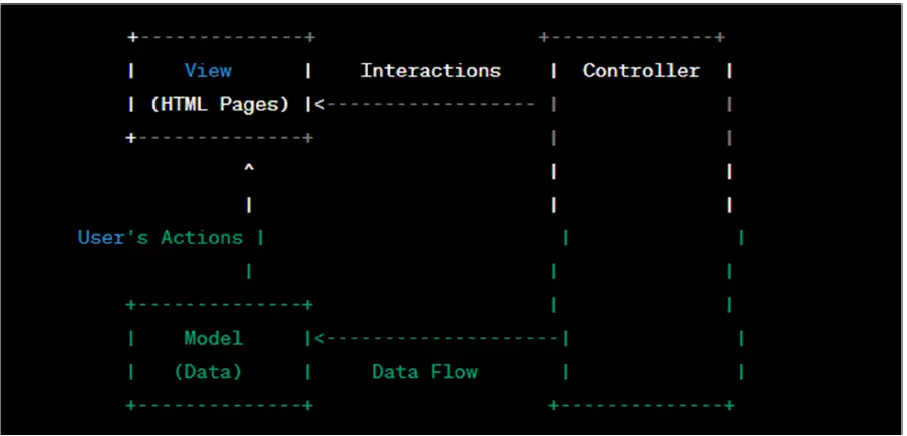
In this illustration, the user interacts with the View (HTML pages), which displays products and allows actions like adding items to the cart. The Controller manages these interactions and communicates with the Model to update and retrieve data. The Model handles the data and business logic, such as managing products, cart contents, and user profiles.
This MVC architecture ensures a separation of concerns, making the application more organized and maintainable. It allows for easier updates, scalability, and changes to the user interface without affecting the underlying data and logic.
(iii) Features of Server-side scripting and related constructs
Ans. Server-side scripting is a programming technique used in web development where scripts are executed on the web server to generate dynamic content that is then sent to the client’s browser. It allows developers to create interactive and data-driven web applications by processing user requests, accessing databases, and performing other server-side tasks. Here are some key features of server-side scripting along with related constructs:
1. Dynamic Content Generation: Server-side scripting enables the creation of dynamic web content that can change based on user input, database queries, or other factors. This allows for personalized and up-to-date user experiences.
2. Data Processing: Server-side scripts can process data submitted by users through forms, validate input, and interact with databases to retrieve, update, or store information.
3. Business Logic: Server-side scripting is where the business logic of an application is often implemented. It allows you to define rules, calculations, and processes that control how data is manipulated and presented to users.
4. Security: Sensitive operations like user authentication and authorization, as well as handling and validation of user inputs, are typically handled on the server side to ensure data security.
5. Database Interaction: Server-side scripts can communicate with databases to retrieve and store data. This is essential for applications that require persistent data storage.
6. Server Resources: Server-side scripting can utilize server resources like memory, processing power, and storage, enabling complex computations that might not be feasible on the client side.
7. Server-Side Frameworks: Frameworks like Ruby on Rails, Django, and Express.js provide tools and libraries for server-side scripting, making development more efficient and organized.
8. Languages for Server-Side Scripting: Common languages for server-side scripting include PHP, Python, Ruby, Java, and Node.js (JavaScript on the server).
9. Related Constructs:
– Server-side Languages: These languages are used to write the server-side scripts. For example, PHP, Python, Ruby, Java, and JavaScript (Node.js).
– Server-Side Frameworks: Frameworks like Django (Python), Ruby on Rails (Ruby), Laravel (PHP), and Express.js (JavaScript) provide structures and utilities to streamline server-side development.
– Database Connectivity: Server-side scripts interact with databases using techniques like SQL queries to retrieve and manipulate data.
– Server-Side Templating: Templating engines allow you to generate dynamic HTML pages by embedding data into templates. This is commonly used in server-side scripting.
– Server-Side Validation: Server-side scripts validate user inputs to ensure they meet specific criteria before processing.
– Session Management: Server-side scripting handles user sessions, maintaining user specific data across multiple requests.
Server-side scripting is crucial for building robust and feature-rich web applications that handle complex logic, data processing, and interactions with external resources like databases and APIs.
(iv) Request and Response in the context of HTTP
Ans. In the context of HTTP (Hypertext Transfer Protocol), requests and responses are fundamental concepts that define the interaction between a client (usually a web browser) and a server. They form the basis for communication in the client-server model of the web. Let’s explore the concepts of requests and responses:
HTTP Request:
An HTTP request is made by a client (such as a web browser) to a server in order to retrieve a specific resource or perform a certain action. A request typically consists of the following components:
1. HTTP Method: Specifies the type of action to be performed on the resource. Common methods include:
– GET: Retrieve a resource.
– POST: Send data to the server (e.g., form submissions).
– PUT: Update a resource.
– DELETE: Remove a resource.
2. Request URL: The Uniform Resource Locator that identifies the specific resource the client wants to interact with.
3. Headers: Additional information about the request, such as the type of data the client can accept (Accept header) or the type of data being sent (Content-Type header).
4. Request Body: Optional data sent with the request, usually in the case of methods like POST and PUT. For example, form data or JSON payloads.
Here's a simple example of an HTTP request:

HTTP Response:
An HTTP response is the server’s reply to a client’s request. It contains the requested resource or information about the success or failure of the request. A response typically consists of the following components:
1. Status Line: Contains the HTTP version, status code, and a brief status message. The status code indicates the outcome of the request (e.g., 200 OK, 404 Not Found).
2. Headers: Similar to request headers, response headers provide additional information about the response, such as content type and length.
3. Response Body: The actual content of the response, which could be HTML, JSON, images, etc.
Here's a simple example of an HTTP response:
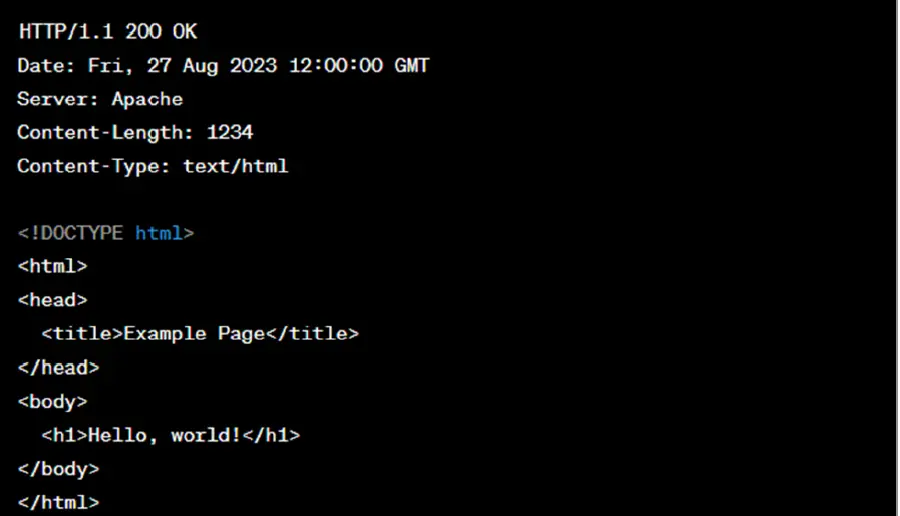
In this example, the response indicates that the request was successful (status code 200 OK) and includes an HTML page as the response body.
In summary, HTTP requests are made by clients to request resources or perform actions, while HTTP responses are the server’s replies containing the requested content or information about the outcome of the request.
(v) GET and HEAD methods of HTTP
Ans. Both the GET and HEAD methods are HTTP request methods used to retrieve resources from a server. While they are similar in purpose, they have different behaviors and use cases. Let’s explore the differences between the GET and HEAD methods:
GET Method:
The GET method is used to request data from a specified resource. When a client makes a GET request, the server responds by sending the requested resource along with the appropriate status code. The response body contains the actual content of the resource.
Example GET Request:

Example GET Response:
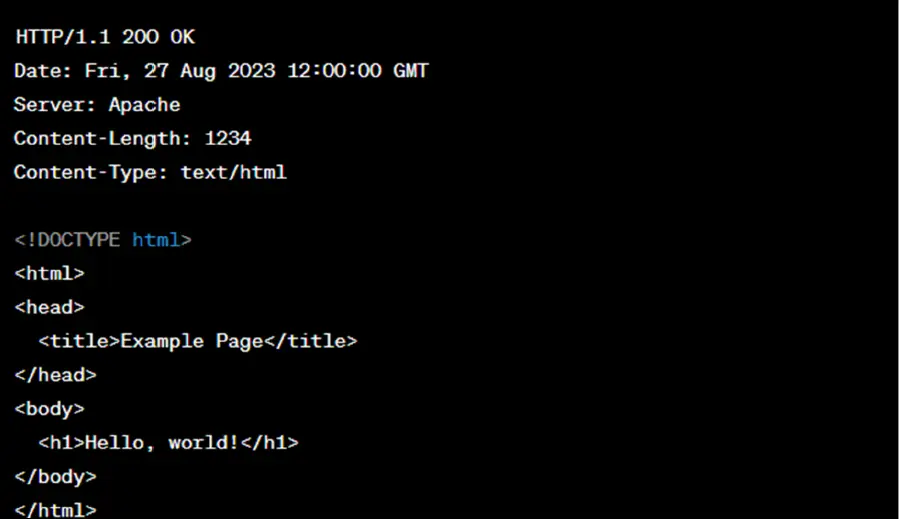
HEAD Method:
The HEAD method is similar to the GET method in that it requests data from a specified resource. However, the key difference is that the server only sends back the response headers, excluding the actual response body. This makes HEAD requests useful when the client only needs metadata about the resource (e.g., content type, length, last-modified date) without the need to download the full content.
Example HEAD Request:

Example HEAD Response:
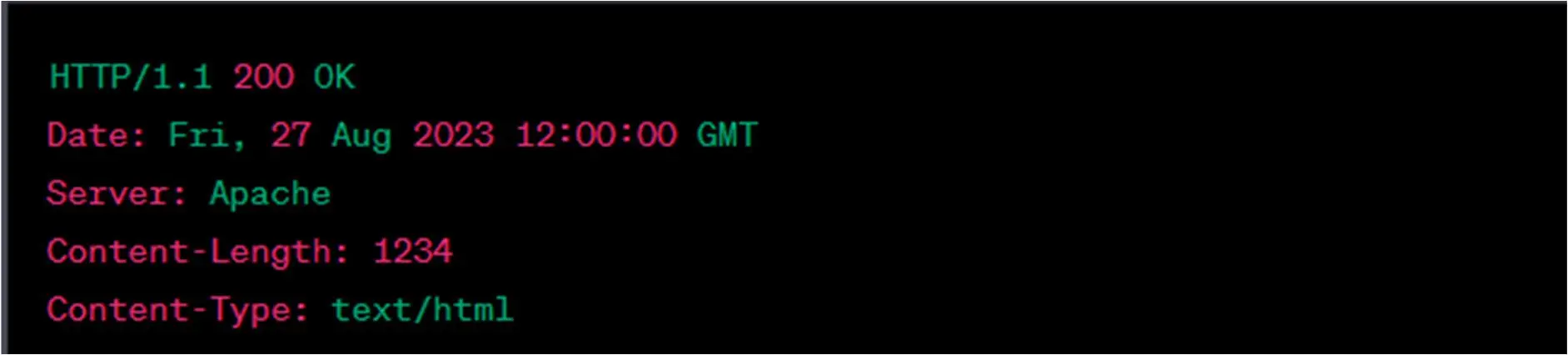
In the example, the response includes headers like content length and content type but does not include the actual HTML content, as would be the case with a GET request.
In summary, the GET method is used to retrieve the content of a resource, while the HEAD method is used to retrieve metadata about the resource without the actual content.